

| Accueil | Présentation | Tous les sujets | Rechercher | |
| Search by word | List of subjects |
Version

The current version of the system has been installed on July, 9th, 2004. It brings numerous corrections to the corpus, and fixes some minor bugs.
Presentation of the system
Preliminary note : Mátala relies on a French-Greek database of two thousand terms. Providing it in an English-Greek version thus implies a heavy translation work. For this reason, the browsing features of the system are only available between French and Greek, starting from the French list of subjects. Only the present presentation of the system has been currently translated to English.
What is it?What is it?
It is probably quite natural, when starting to learn a foreign language, to make sheets of vocabulary, that we enrich little by little, following the lessons... The corresponding result is a list of words and expressions organized according to a somehow thematical logic, since it has been elaborated along with the subjects tackled by the lessons. As this vocabulary grows though, it becomes more and more difficult to find, in these notes, a word learned in a preceding lesson.
In a language such as modern Greek, where roots, prefixes, suffixes and other transformations of radicals are frequent, and where the mechanism of declensions modifies articles, nouns and adjectives, the necessity of linking a new word with another one, learned before, soon reveals necessary. Indeed, memorizing a word build on the same roots than other terms already known is probably easier than learning a totally new word: it will for sure be easier to memorise τακτοποιώ if we already know τάξη, and if the semantic and morphological relation existing between these two words is pointed out.
When revising or learning vocabulary willingly, one might also wish to set up thematical folders; besides, such a classification is a good entry point when searching a forgotten or unknown word. Finally, as soon as it somehow enriches, the corpus of vocabulary set up by the one who learns a foreign language rapidly needs "navigational" possibilities: from the new towards the already known, but also, by curiosity, from the already known towards the unknown. Examples of former situation are numerous: we already know a word bearing the same "meaning" than the one we just encountered... but there is probably a little difference in the meaning or the usage; or, we thought this word meant something else (but maybe it has several different meanings?); or, we knew the adjective, and here is the corresponding verb; one can also mistake one word for another (νόμος and νομός...) - and, particularly in this case, it might be very useful to link the known word and the new one.
Mátala is an attempt to set up a browsing system in a bilingual, French-Greek lexicon. Mátala is clearly a mock-up, a prototype: our aim here is not to provide a final system, operational and ready-to-use, but to evaluate the interest of such a system, against two criteria: on the one hand, evaluate the actual possibilities of browsing in such a system (maybe 80 % of the words will finally be linked with nothing?); on the other hand, validate the concepts (data modelling), on which the system relies, against the reality of a corpus quite small, but yet complex. Mátala in also, in Crete, at the the extremity of the plain of Messará, a small harbour surrounded with limestone cliffs; during the seventies, the village became somehow famous while hosting, in the neightbouring caverns, the biggest hippie communauty in Europe. It is now a touristic place; it is still located at a few kilometers from the beach where Zeus, in the form of a bull, might have kidnapped the beautiful Europe.
Users guidelines
The entry point of the system is the List of subjects (in French).
It is possible to click on more or less all French and Greek terms displayed by the system, in order to get more information on them... The French terms which can be clicked are always signaled by a particular typography (blue and/or italics).
Generally speaking, the terms on which it is possible to click blink when the mouse passes over them.
What can be done today...
The initial corpus of the system consists in approximately two thousand words and expressions typed in by a beginner, during his first learning stages of modern Greek, with no preliminary intention to set up a computer-based system. For this reason, nouns can appear in a plurar form, or declined; verbs can be conjugated, and adjectives can be agreed, even if we tried to normalize al these terms as much as we could. Expressions are most of the time usage examples for terms also defined individually in the database.
The following browsing features are possible:
Browsing based on semantic criteria
- browse in a simple, hierarchical network of subjects, sub-subjects, etc. In the current version of the system, this network supports multiple parents and children for each subject (e.g. the subject "Musique", music, will be found as sub-subject of "Les arts, la culture", Arts and culture, and "Entendre, écouter", Hear and listen);
- see all the terms classified in a given subject. When a term appears in a subject, it also appears in the list of terms of the parent subjects of this subject (λεμονιά, lemon tree, being classified in the subject "Arbres", trees, and "Arbres" being child of subject "Plantes", plants, λεμονιά will also appear while asking for the content of subject "Plantes");
- see all the subjects in which a given term is classified (or, more precisely a "sem", see below), in order to be able to access the other terms attached to the same subject(s);
- see, in the mother tongue, the list of all the possible meanings of each term of the learned language (ικανός will lead to: suffisant (sufficient), apte à (able to), etc.). In the forthcoming, we will refer to this situation as "polysemy", though this might be improper;
- on the contrary, see the other terms of the learned language having the "same" meaning than a given term of this language (σημαντικός, important, will then lead to σπουδαίος). We will call this situation "synonymy".
Browsing based on morphological criteria, and grammatical information
- see, from a given term of the learned language, the other terms built on the same root(s). For an expression, this action did not seem to make much sense, and we replaced it with an access to each of the terms appearing in the expression, and individualy identified in the database (all the actions mentioned above thus become available for each of these terms);
- roots themselves are reminded between parentheses, and the list of all terms built on a given root can also be accessed;
- for several terms, we had additional grammatical informations. These data are mostly, for verbs, the conjugation and, for adjectives, the agreement of singular nominative, when this information was present in the data. But, unfortunately, declination of nouns won't be found here, except for some non-typical cases (το κρέας, το παρελθόν)...
What could be possible tomorrow...
We present here the first version of the system. Many improvements can therefore be concieved:
1. an alphabetical presentation of subjects, greek terms and translations;
2. computer-aided authoring features of the corpus;
3. streamed listening of the pronounciation of each greek term;
4. english translation of mother tongue data (currently in french). In particular, this translation would allow us to further validate the robustness of the concepts on which we based the logical modelling of data (see below).
Third point above is significantly prospective: a system such as present one only makes sense if the data it relies on do not contain doubles. When a user adds the subject "arbre" (tree) in the database, he should be informed that there already exists a subject "Arbres" (Trees). And when he inputs the term συνείδηση, the ideal system should automatically detect the roots συν- and ειδ-, and create the corresponding links with the new term or, at least, suggest them to the user... Generally speaking, authoring and enrichment of such structured corpuses seems to us the central question raised by such systems, and the main obstacle to a realistic, real scale set up of them: as long as such "intelligent" tools for linguistic analysis are not here to assist the user during corpus enrichment phases, keeping such databases alive remains an intricate, endless task.
A few theoretical elements
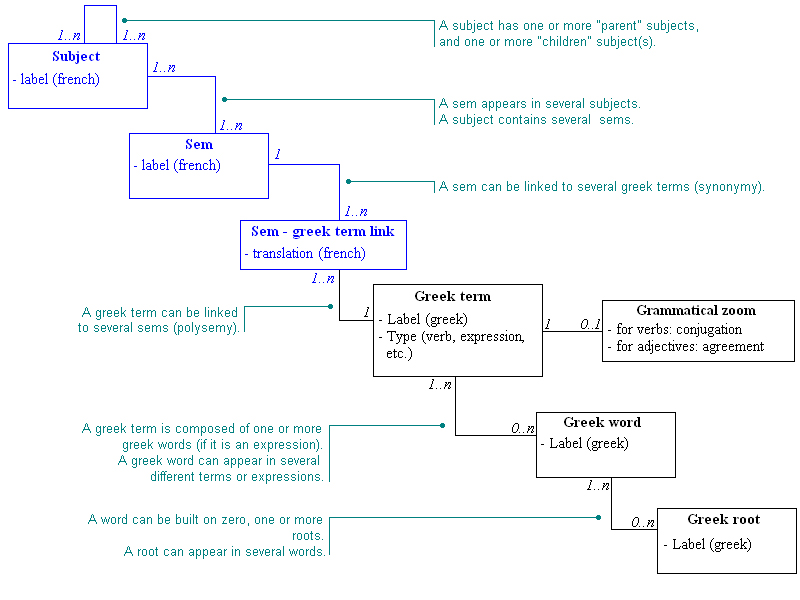
Sems
The central issue of a bilingual system such as Mátala is of course the translation: how will we manage the different possible translations of a given greek term? How will we manage the various ways to say in Greek an idea initially expressed in French? In order to tackle this problem, we made the following assumption: if it is possible to translate an idea (from Greek to French or the other way around), then this idea can be expressed in both languages.
Of course, this first assumption is already a reduction: objects or concepts that do exist only in one of the two cultures will only be translatable through a paraphrase consisting in a small description of this object (the domain of cooking is rich in such examples: τζατζίκι, κολοκυθοκεφτέδες...). More complex situations can be found, where a word or expression can only be expressed in the other language through an accumulation of complementary translations: προλαβαίνω, avoir le temps de (to have time to do something), arriver à temps (to arrive in time) which, furthermore, is transitive (πρόλαβα το τραίνο, j'ai réussi à avoir le train (I managed to get the train), i.e. : in spite of my being late); an other example is given by prepositions bearing a double logical and temporal meaning: αφού (puisque ("since" in a logical meaning) and après que (after)), άμα (si (if), quand (when)).
In a second phase, we tried to refine these concepts in order to come to semantic, unitary atoms, carrying no ambiguity, and shared by both languages. In the following, these semantic atoms are called sems. Maison (house), facile (easy), découvrir (quelque chose d'inconnu) (to discover something unknown), plaine de Thessalie (plain of Thessaly) are sems. But, for example, we distinguished sortir (quelque chose de quelque part) (take something out of something/somewhere) and sortir (quelque part) (go out somewhere), because sortir (take out or go out) is ambiguous by itself in French. Sems are given a label, in French. This label is unique, and ambiguities coming from the French language are eliminated, as shown in the preceding examples, by use of precisions between parentheses. We will see later that these labels are only used for identification of the sem: they are not used to provide the user with the translation of the greek terms.
Subjects
Sems constitute the joigning point between the two languages: on the semantic side (or, in an equivalent way, on the side of the mother tongue), sems can be classified in a hierarchical network of subjects, which are also presented in the mother tongue. (In fact, subjects are also sems, only corresponding to cognitive objects of abstract, generic nature; the network of subject could thus probably be set up directly at sem level.) From the point of view of the user, the entry point of the system is precisely this network of subjects: it is possible to browse from subject to subject, to see all sems classified in a given subject, and all subjects in which a given sem is classified.
Greek terms and greek words
On the side of the learned language and its morphology, the central data consist in greek terms, which are a word or an expression. Each term of the learned language is linked to one or more sems, which correspond to the various ideas that this term can carry ("polysemy"): αδειάζω is linked with sems vider (to empty something) and se vider (something is emptying). The other way around, a sem can be linked to several terms, in order to manage synonymy: ευχαριστιέμαι and χαίρομαι are linked with the same sem prendre plaisir (to enjoy oneself).
Links between sems and greek terms
These links between sems and greek terms are the main basis for display of data to the user. In fact, when we consider one of these sem-term links, we have, not only the term, but also one of the sems to which it is linked. We thus have an information richer than the one provided by the only lexicon of greek terms: the sem to which the term is linked provides a semantic information that informs on the way the user reached this greek term. This allows to provide the user with a contextual translation of the learned term, taking into account the itinerary which led him to this term. We thus avoid the classical drawback of the lexicon which, totally lacking of contextual information, cannot offer, for each term, anything else than a flat list of all its possible translations.
For example, ανοιχτός will be translated by clair (light, for a colour), ouvert (opened) or allumé (turned on, for a television, a radio) depending on the fact that we arrived on the term through subject "Couleurs" (colours), "Ouvrir, fermer" (open, close), "Allumé et éteint" (turned on, turned off) (but, in each of these three cases, the other meanings will be visible); of course, the morphological section (roots, agreement of adjective, etc.) will remain the same for these three displays.
In the case the greek term is an expression (or a composed word), it is linked with all the sems that can be identified in the expression : Τι ώρα ; , À quelle heure... ? (What time, when... ?), is linked to sems quel ? (what, which?) and heure (hour). In this case, labels of sems cannot be used for translation, because what we want to translate is a complex object, which meaning results from a grammatical combination of sems (of course, grammatical issues are willingly excluded from our purpose).
Finally, neither sems nor terms are sufficient for providing the information required for a proper translation; this is why the translation in mother tongue of the terms of the learned language is beared by the sem-term link itself.
Greek roots
In turn, greek terms are split in greek words (so that the different words can be identified when greek term is an expression). Today, the type of words (nouns, adjective, etc.) is managed along with the greek term. This is a design error: this information should logically be carried by greek words.
Finally, there exists a corpus of greek roots: each greek word can be linked to the various roots on which it is built.
These links allow the user to browse, starting from a given word, to the other words built on the same root(s), or towards the expressions where this word is used. In fact, for ergonomic reasons, this browsing feature is provided directly from the display of greek terms; words and roots are only presented separately if a choice is required from the user, i.e. when the displayed term includes more than one word (case of an expression), or if several roots can be identified in a single word. In these situations, intermediate lists of words (or roots) are displayed, so that the user can do the browsing of his choice.
In the schema below, we depict all these data, and the relations taking place between them, on which all browsing features of Mátala are based.
Technical elements, supported plateforms, known bugs
The current system relies on a PHP/MySQL technology. This database is hosting the data in a relational structure exactly following the logical model depicted above.
Configurations on which the system works are at least:
- Windows (NT, XP and probably others) and Internet Explorer;
- Mac OS X and Safari or Mozilla. Internet Explorer seems to encounter problems on Mac OS X. Mac OS 9.x has not been tested ;
- Linux (RedHat 7.x and 8) and Mozilla.
Known bugs:
1 - In the display of term-sem links (main display), the list of elements of same roots is not limited. When more of approximately 15 elements are displayed, the liste superimposes over the term itself, or over the grammatical zoom (verb conjugation or adjective agreement).
Bugs and mistakes can be signaled by e-mail to Pascal Mullon. This e-mail is also accessible from the page in which the problem is discovered, by clicking on the  icon on top of the page.
icon on top of the page.